自然语言处理期末复习
自然语言处理复习笔记,如有错误还请各位大佬指出。
语义知识部分我没有整理,但是感觉必考,考试的时候最好打印上语义知识的PPT。
文末可以下载本文的markdown源码。
更正(2019年7月8日07:59:55):First函数那边把终结符写成非终结符了,现在已经改正好。
范畴文法
基本范畴
只有两种基本范畴:S和N。
S相当于"句子",N相当于"名词"。
范畴构造符
“”表示“左缺”;“/”表示“右缺”。
例1(第二章PPT第22页)
B和C是两个词,C的句法类型是γ,BC的功能相当于β,则B的句法类型是β/γ,读作β右缺γ。
例2(第二章PPT第23页)
求John never works这句话中never的范畴表达式?
- John是人名,范畴表达式为N;
- John never works是一句完整的话,所以范畴为S;
- 由12知,never works范畴N;
- never在这一句话中起修饰限定作用,拿掉never是John works,同样是完整的话,John works范畴为S;
- 由14知,works范畴是N;
- 由35知,never范畴是(N)/(N)。
范畴
一个语言成分的范畴(类型)由基本范畴S,N加上范畴表达式构造符“”,“/”,括号“(”,和“)”构成。
更多范畴标注请见第二章PPT25页。
例题
题目
给出and、that的范畴类型表达式。
分析
and和that在不同的句子中有不同的范畴类型,需要自己造句,然后分析其范畴类型。
答案
and: I like red and blue.
- red and blue是like的宾语,范畴为N;
- red和blue是名词,范畴为N;
- 由12知,and的范畴为N/N。
that: I am so glad that you satisfied with your new life.
- 原句为一个完整句子,范畴为S;
- you satisfied with your new life为完整句子,范畴为S;
- 由12知,that的范畴为S/S。
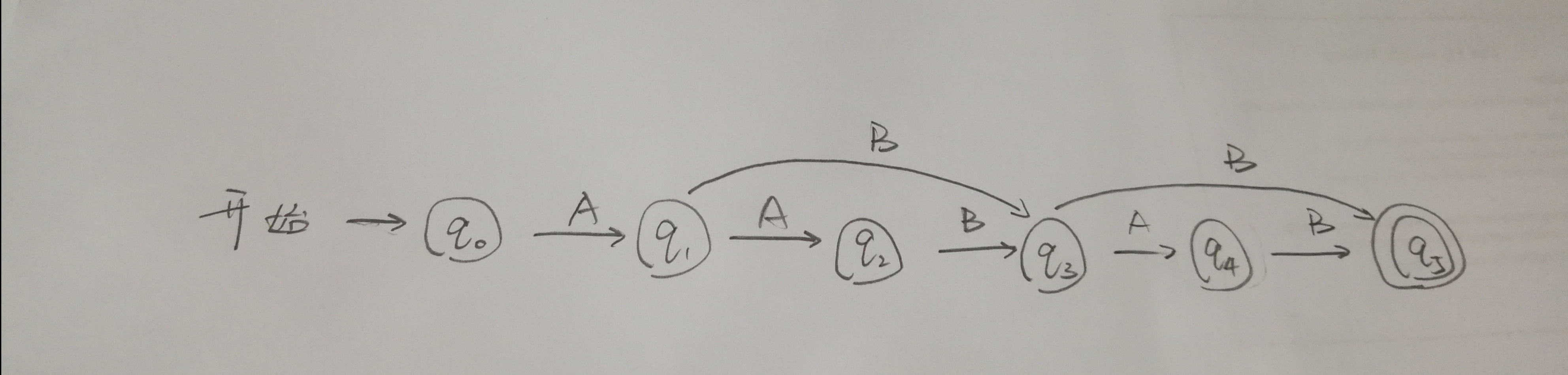
有限状态自动机
例题
题目
构造一个有限状态转移网络(有限状态自动机),使之可以接受AABB,ABB,ABAB.
答案
CFG文法
上下文无关文法与上下文相关文法[1]
上下文无关文法就是说这个文法中所有的产生式左边只有一个非终结符,比如:
S -> aSb
S -> ab
这个文法有两个产生式,每个产生式左边只有一个非终结符S,这就是上下文无关文法,因为你只要找到符合产生式右边的串,就可以把它归约为对应的非终结符。
比如:
aSb -> aaSbb
S -> ab
这就是上下文相关文法,因为它的第一个产生式左边有不止一个符号,所以你在匹配这个产生式中的S的时候必需确保这个S有正确的“上下文”,也就是左边的a和右边的b,所以叫上下文相关文法。
例题
题目
设文法G由如下规则定义(符号 | 表示或的意思):
S→AB A→Aa | bB B→a | Sb
给出下来句子形式的派生树
- baabaab
- bBABb
分析
文法G给出的三条规则叫做产生式。
先分析推导过程,只要在需要分析的句子中找到符合产生式右边的串,都可以转为左边的非终结符,这一过程叫做规约。
从左向右扫描,每成功归约一次,重新从左向右扫描。
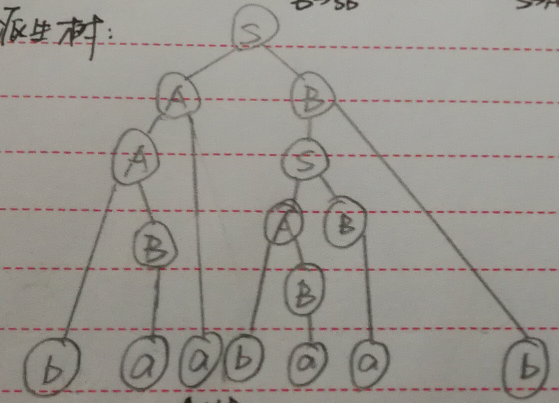
答案
baabaab
- a ==> B
- bB ==> A
- Aa ==> A
- a ==> B
- bB ==> A
- a ==> B
- AB ==> S
- Sb ==> B
- AB ==> S
派生树:
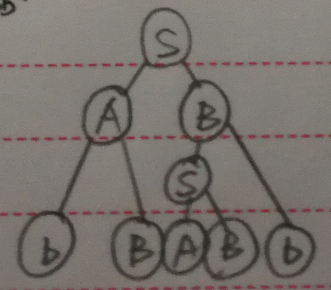
bBABb
- bB ==> A
- AB ==> S
- Sb ==> b
- AB ==> S
派生树:
自顶向下分析法
自顶向下的方法又称为基于预测的方法。
先产生对后面将要出现的成分的预期,然后再通过逐步吃进待分析的字符串来验证预期。
- 如果预期得到了证明,就说明待分析的字符串可以被分析为所预期的句法结构。
- 如果某一个环节上预期出了差错,那就要用另外的预期来替换(即回溯)。
- 如果所有环节上所有可能的预期都被吃进的待分析字符串所“反驳”,那就说明待分析的字符串不可能是一个合法的句子,分析失败。
自底向上分析法
自底向上的方法也叫基于归约的方法。
这种方法是先逐步吃进待分析字符串,把它们从局部到整体层层归约为可能的成分。
- 如果整个待分析字符串被归约为开始符号S,那么分析成功。
- 如果在某个局部证明不可能有任何从这里把整个待分析字符串归约为句子的方案,那么就需要回溯。
- 如果经过回溯始终无法将待分析字符串归约为S,那么分析失败。
例题
题目
G是一个CFG文法:G = ({S,X}, {a,b,c,d,e,f,g}, S, P)
其中P定义如下:
- S →a X c
- S →b X c
- S →b X d
- S →b X e
- S →c X e
- X →f X
- X →g
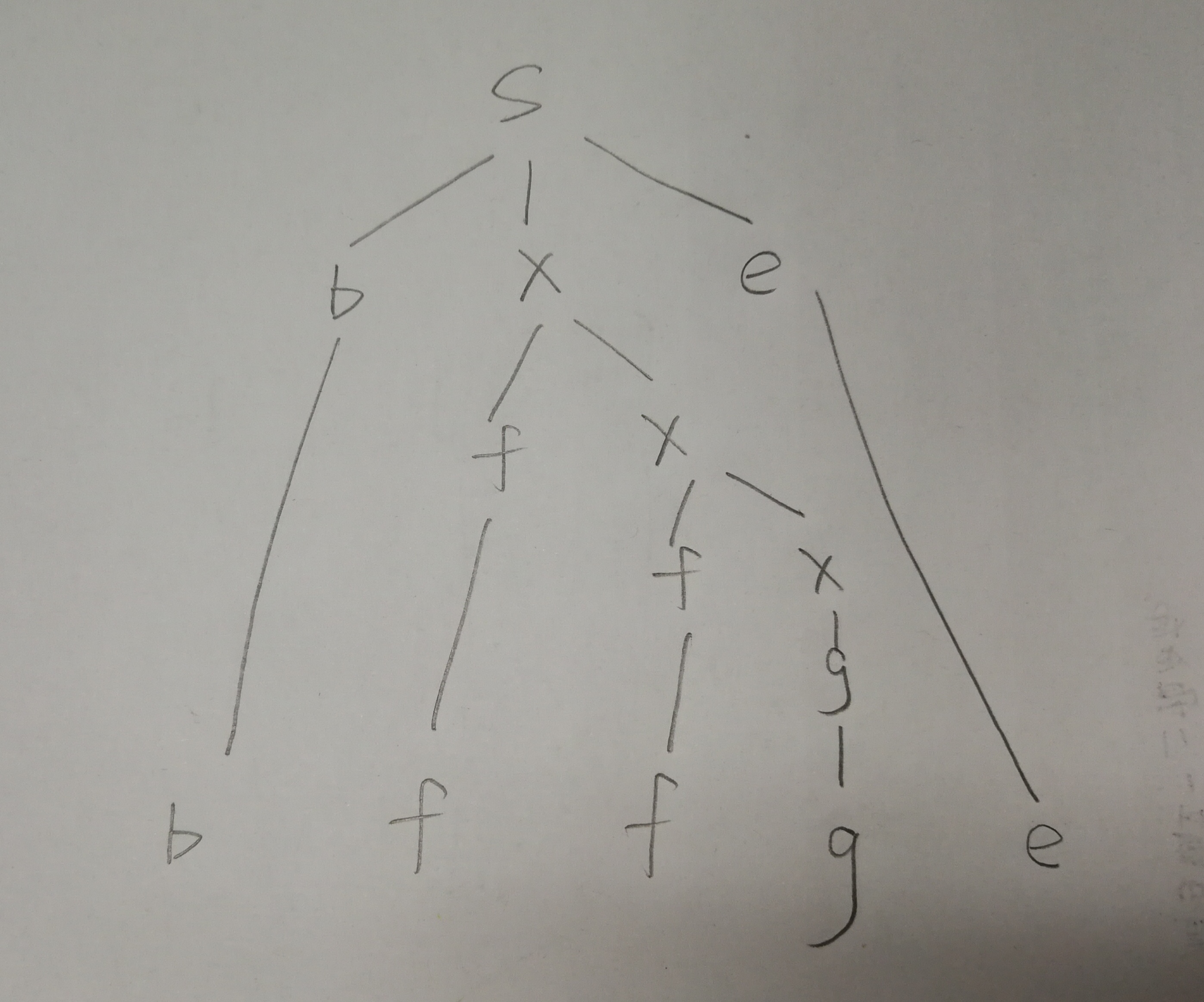
采用你所选择的分析器处理字符串“bffge”,写出整个运行流程。
分析
自顶向下分析法中,从左向右扫描可以使用的规则,记录每一步的操作。如果没有可用规则但是句子还没到达终点,就进行回溯,回到可以使用规则的点。自底向上也一样。
答案
回溯的部分太多,我就跳过了。第三章ppt420页有很好的自顶向下demo,3045页有自底向上demo,我就把最终结果画一画。
线图分析法
处理流程
当前句子成分称为key,需要做2件事情:
是否有以key开始的规则,如果有就开启一条活动弧;
第三章ppt47页有demo
当前key是否可以扩展之前的活动弧,如果可以就扩展之前的活动弧。
第三章ppt48页有demo
如果扩展后,某条规则被匹配完成了,那么就成为了一个新成分(该规则的左边符号)。对于新成分,同样检查这两件事,即有没有以新成分开始的规则,还有新成分能不能扩展之前的规则。
例题
题目
给定如下规则:
| 1. S → NP VP | 4. NP → ADJ N |
|---|---|
| 2. NP → ART ADJ N | 5. VP → AUX VP |
| 3. NP → ART N | 6. VP → V NP |
使用线图分析法分析 The large can can hold the water这句话。
分析
没啥好分析的,按照上面的处理流程直接做。
答案
先初始化状态,把每个词所有的词性写在这个词的上面。

key=The
词性:ART
开启活动弧:
- NP → ART 。ADJ N
- NP → ART 。N
不能扩充活动弧
key=large
词性:ADJ
开启活动弧:
- NP → ADJ 。N
扩充活动弧:
- NP → ART ADJ 。N
key=can
词性:N
不能开启活动弧
扩充活动弧:
- NP → ART ADJ N。匹配完成,新加入成分NP1
- NP → ADJ N。匹配完成,新加入成分NP2
词性:V
开启活动弧:
- VP → V 。NP
不能扩充活动弧
词性:AUX
开启活动弧:
- VP → AUX 。VP
不能扩充活动弧
新成分NP1
开启活动弧:
- S → NP 。VP
不能扩充活动弧
新成分NP2
开启活动弧:
- S → NP 。VP
不能扩充活动弧
key=can
词性:N
不能开启活动弧
不能扩充活动弧
词性:V
开启活动弧:
- VP → V 。NP
不能扩充活动弧
词性:AUX
开启活动弧:
- VP → AUX 。VP
不能扩充活动弧
key=hold
词性:N
不能开启活动弧
不能扩充活动弧
词性:V
开启活动弧:
- VP → V 。NP
不能扩充活动弧
key=the
词性:ART
开启活动弧:
- NP → ART 。ADJ N
- NP → ART 。N
不能扩充活动弧
key=water
词性:V
开启活动弧:
- VP → V 。NP
不能扩充活动弧
词性:N
不能开启活动弧
扩充活动弧:
- NP → ART N。匹配完成,新加入成分NP3
新成分NP3
开启活动弧:
- S → NP 。VP
扩充活动弧:
- VP → V NP。匹配完成,新加入成分VP1
新成分VP1
不能开启活动弧
扩充活动弧:
- VP → AUX VP。匹配完成,新加入成分VP2
新成分VP2
不能开启活动弧
扩充活动弧:
- VP → AUX VP。匹配完成,新加入成分VP3
- S → NP VP。匹配完成,新加入成分S2
- S → NP VP。匹配完成,新加入成分S1
新成分VP3
不能开启活动弧
不能扩充活动弧
新成分S2
不能开启活动弧
不能扩充活动弧
新成分S1
不能开启活动弧
不能扩充活动弧
最终结果如下图

例题二
题目
用自底向上线图分析法分析“I saw a girl with a telescope”。
规则为:

答案
和上面的思路一样。

GLR分析法
LR分析过程
基本思想
LR分析算法根据两个参数决定下一步分析动作:
- 利用预读字符( Lookahead )
- 当前状态
First(x)函数——实现预读
First(x)的表达式为 \[ First(x)=\{ \alpha|x\Rightarrow \alpha \beta,\alpha \in V_T, x,\beta...\text{算了太长不写了,写了也看不懂} \} \] First(x)就是先找到以x开始的规则,然后取箭头右边的第一个终结符。First函数返回是一个包含第一个终结符的集合,所以是第一个终结符加上大括号,表示集合。
比如有规则NP → N,那么First(NP)就是取箭头右边第一个终结符,就是N,所以First(NP)={N}。
再比如有规则S → NP VP,那么First(S)就是取箭头右边第一个终结符,箭头右边第一个符号是NP,但是他不是终结符,要继续深入找终结符,找到规则NP → N,NP的第一个终结符是N,所以First(S)={N}。
状态构造方法
1.添加一条新规则:\(S’ \rightarrow S\),并且把S‘定义为文法开始的符号;
2.写状态0,状态0的第一条二元组为<\(S’ \rightarrow o\ S, \$\)>
3.完成当前状态,当前有二元组<\(x \rightarrow \alpha \ o \ y \ \beta, \ t\)>,尝试找以y开头的规则,找不到就算了,如果找到了以y开头的规则,那么在当前状态中添加一条二元组<\(y \rightarrow o \ γ,\ t’\)>,而t’的值为:
若β为空,那么t‘=t;
若β不为空,那么t‘为first(β);
4.如果有两个二元组第一个元素相同,第二个元素不同,即<\(y \rightarrow o \ \gamma,a\)>和<\(y \rightarrow o \ γ,\ b\)>,那么就使用“|”符号合并为<\(y \rightarrow o \ γ,\ a|b\)>
写完当前状态后,看看当前状态遇到哪些词性可以扩展,比如<\(NP \rightarrow o \ N, V\)>遇到N可以扩展,那么就添加一个遇到N的状态,接下来的操作跳到第3步。
简单例子在第三章第二个ppt8~12页。
分析表
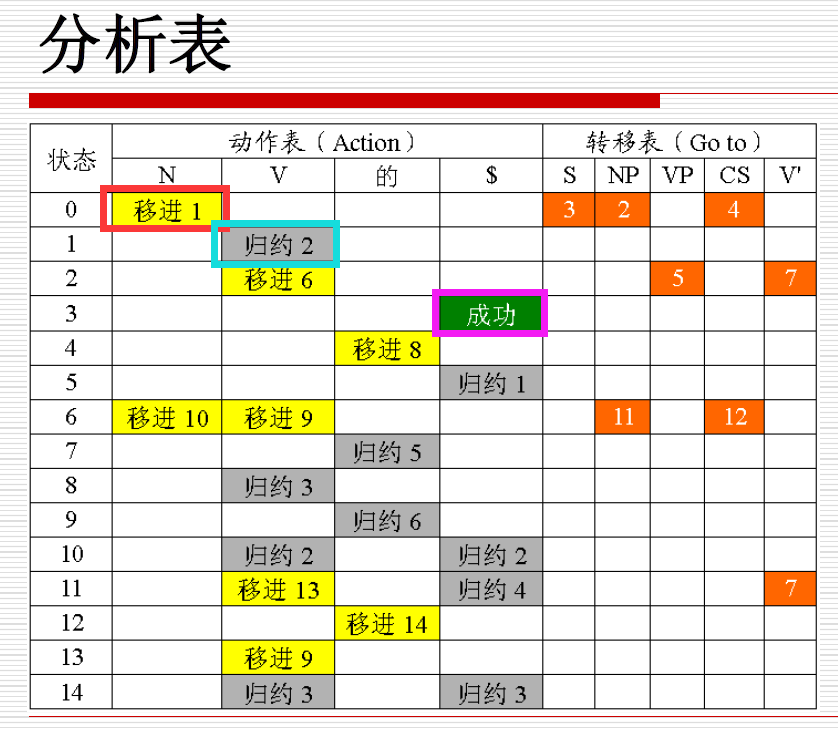
如果状态s遇见符号x转移为状态s’,那么就在转移表中当前状态行,第x个符号列写入转移状态号s'。
比如状态0遇见N转移为状态1,那么就在第0行第N列写入1。
如果x是终结符,那么还要在前面加入“移进”两个字。(见例图红色框)
2.如果当前状态有一个二元组匹配完了,二元组的形式为<\(x \rightarrow \alpha \ o,\ t\)>
在当前状态行,第t个符号列,写入“归约”,再写上完成的规则号i
比如
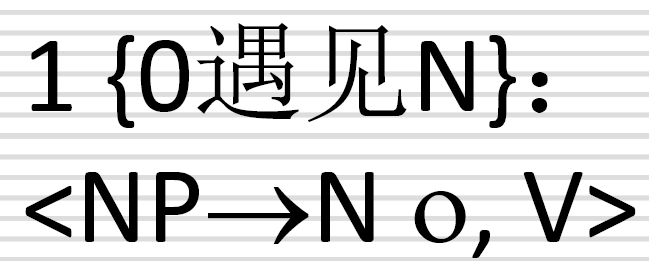
<NP → N 。, V>这个二元组匹配好了规则2:NP → N,那么就在当前状态行,第V个符号列写归约2。(见例图蓝色框)
如果包含二元组<S’→S o, $>,那么就在当前状态行,$列写成功。(见例图紫色框)
反复执行123条,直到所有状态都遍历。
【注】如果一个格子里要写多个部分,比如既要写移进又要写归约,那就都写进去,用“/”符号分隔开。
GLR分析过程
符号含义
- 圆圈●:代表状态,上面的数字表示当前在哪个状态。
- 方框■:代表分析树的节点,上面的数字表示已经形成了哪个节点。
- action:一串●-■-●-…-■-●-■-后面跟着的[s/r]表示下一步要做的事情。
- Next Word:表示下一个要处理的词性,每个句子最后都有一个结束符$,所以句子最后一个词性处理完后,Next Word为$。
- Index:这是我自己定义的数,值为分析树中最大编号+1,初始值为0。每执行一次移进或者归约,分析树中就会多一个节点,相应的index也会自增1
- 分析树:最后用于构建树的节点信息,每个节点的编号依次从0开始递增。就是ppt上的这个部分:

初始化
- 初始化为状态0,即●上面一个0。
- Next Word:第一个词的词性。
- 动作,查分析表当前状态第Next Word列的内容(比如[s3]或者[r7]),写进去。
移进
动作为s表示移进操作,处理过程:
- 将Next Word的词性放进分析树中,编号为index
- 加入一个■,上面数字写index,和刚刚放进分析树中节点编号相同
- 加入一个●,上面数字写action的移进状态号,这也是当前状态号
- Next Word改为需要分析语句中下一个词的词性
- action改为分析表中,当前状态第Next Word列的值
归约
动作为r表示归约操作,处理过程:
看action中,归约的规则号。比如r6就查第6条规则,比如NP → Det N
箭头左边的称为归约节点
箭头右边的称为归约成分
此规则箭头右边有几项,就回退几个状态。比如箭头右边有2项,就回退2个状态:

转为

将此规则箭头左边的一项放入分析树中,编号为index,括号里写上几个数字,表示由哪几个节点归约而成
比如写上10[NP(3,4)]
加入一个■,上面数字写index,和刚刚放进分析树中节点编号相同
查询分析表,当前状态行,归约节点列的转移状态号
加入一个●,上面数字写上一步查到的转移状态号,这也是当前状态号

action改为分析表中,当前状态第Next Word列的值
分支
如果action有1个以上的操作,要分别处理。比如action为[s8/r3],那么就分别当做这里只有s8和r3,分开处理,然后再把相同节点合并:

转为:
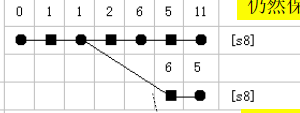
从左到右,●0 ■1 ●1是相同的,就可以合并,其余的不同,就开分支。
歧义压缩
需要两个条件,就可以进行歧义压缩:
- ■两侧的状态号相同
- ■节点内容相同
歧义压缩会把路径多合一,也会把分析树中的节点多合一。
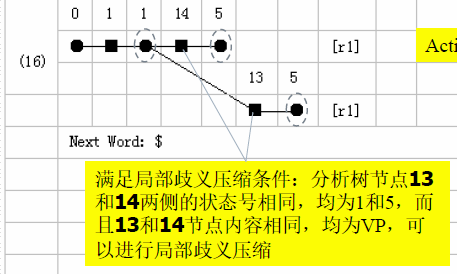
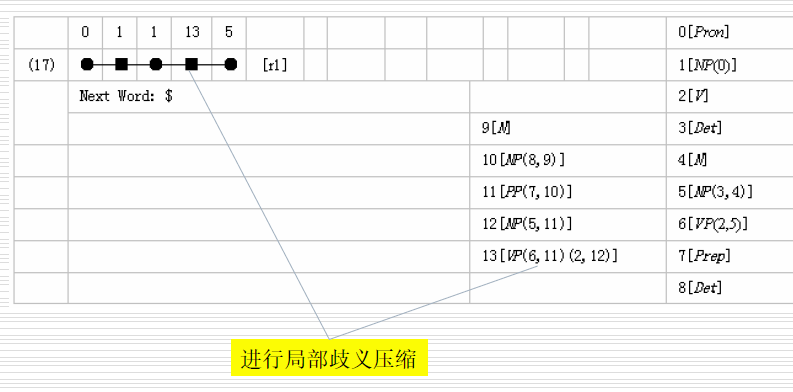
完成
当action是acc或者成功时,那么就分析完成了。
根据分析树构造分析树
什么鬼标题,但我不知道该怎么表达会比较好。
就是根据
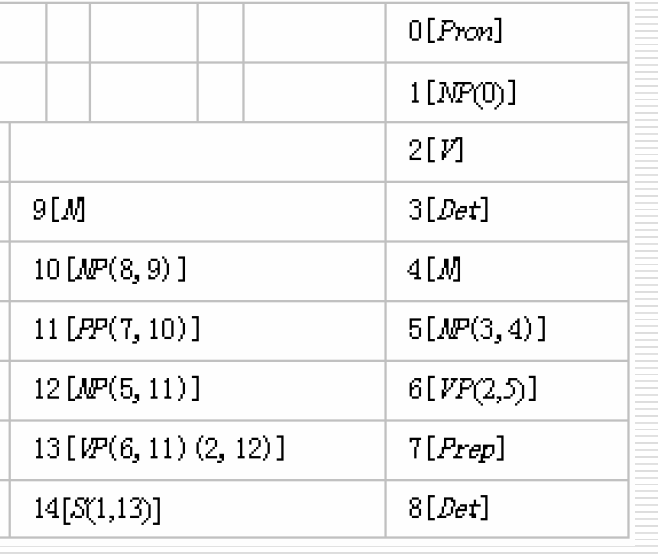
画出
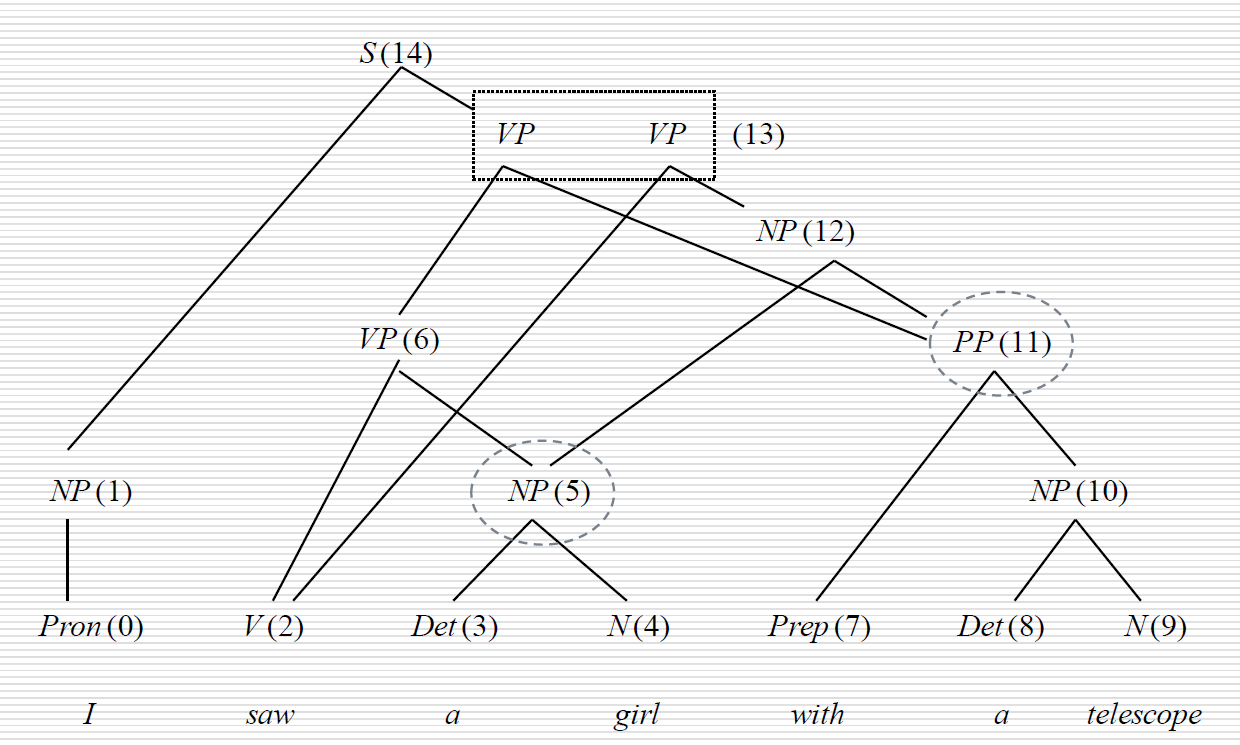
懂我意思就行。
这一步很简单,就是根据表中信息,一步一步画出树来,节点编号放在节点内容后面了。
非归约节点是可以直接画在词的上面的,比如0[Pron]就直接在I上面写上Pron(0)就好
归约节点由非归约节点组成,比如6[VP(2,5)],那么就把编号2和5的节点合成VP(6)
进行歧义压缩的节点就分成多个,用框子框起来:
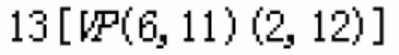

致谢
感谢杨凯同学、王海杰同学在此门课程上对我给予了莫大帮助!
Reference
- 应该如何理解「上下文无关文法」? - 徐辰的回答 - 知乎 https://www.zhihu.com/question/21833944/answer/40689967
源码
本文的markdown源码可以在这里点击下载
