Google Kick Start 2020 Round A
记录一次Google Kick Start的参赛经历,题目都很有意思,我的解法更有意思(?!)。比赛结果嘛,太菜了太菜了,不过好歹是进入了Round B。
官方链接在这里,真的推荐找实习的同学把题目做一下,比LeetCode好玩的不知道哪里去了。
Allocation
原题
Problem
There are N houses for sale. The i-th house costs Ai dollars to buy. You have a budget of B dollars to spend.
What is the maximum number of houses you can buy?
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case begins with a single line containing the two integers N and B. The second line contains N integers. The i-th integer is Ai, the cost of the i-th house.
Output
For each test case, output one line containing
Case #x: y, where x is the test case number
(starting from 1) and y is the maximum number of houses you
can buy.
Limits
Time limit: 15 seconds per test set. Memory limit: 1GB. 1 ≤ T ≤ 100. 1 ≤ B ≤ 105. 1 ≤ Ai ≤ 1000, for all i.
Test set 1
1 ≤ N ≤ 100.
Test set 2
1 ≤ N ≤ 105.
Sample
Input
3 4 100 20 90 40 90 4 50 30 30 10 10 3 300 999 999 999
Output
Case #1: 2 Case #2: 3 Case #3: 0
In Sample Case #1, you have a budget of 100 dollars. You can buy the 1st and 3rd houses for 20 + 40 = 60 dollars.
Note: Unlike previous editions, in Kick Start 2020, all test sets are visible verdict test sets, meaning you receive instant feedback upon submission.
题目大意
现有N套房子在卖,第i套房子的价格为Ai,而手头的预算有B,问最多可以买几套房。
分析
一开始我还以为是01背包问题,后来一想不对,这题好像不用那么折腾,一个贪心策略就能解决。我的贪心选择策略是,每次都选价格最便宜的房子,直到手里的钱都卖不起最便宜的房子,这时买到手的房子一定最多。
我用大白话证明一下:
首先,此问题具有最优子结构性质:意思是说,假设我手里有100块,最多可以买10套房,在我买最后一套房之前,我已经花了80块钱买了9套房。
最优子结构是,如果100块买10套房是最优解,那么80块买9套房一定是最优解。
反证一下,假设80块不止可以买9套房,80块实际上能买10套房,那么我花完80块的时候已经有了10套房,再买剩下的一套,总共花100块买了11套房,与100块买10套房是最优解矛盾,所以假设不成立。
其次,我每次都选当前最便宜的房(买完不能重复买),最后一定是最优解。
反证,如果存在一个更优的解法,即不买最便宜的房也构成了最优解。比如现在有30,40,50三种房,我选最便宜的30,更优解选择40,那么这两种解法在这一步得到了相同数量的房子,而我所剩的存款比更优解更多,所以我一定可以在接下来的买房中买到和更优解相同数量的房子,最终我的买房数量和更优解相同,那么我同时也是一个最优解。
代码思路
排个序,按最便宜的买,买不起为止。
代码
1 |
|
官方解法
We want to buy as many as possible houses. Intuitively, we can keep buying the cheapest house. The rationale is to save money at each step so we could buy more in the end. One way to implement this strategy is to sort all the houses by prices from low to high and then buy houses one by one until we run out of money.
The sorting part has O(N log N) time complexity and the processing part has O(N) time complexity. Using counting sort could reduce the sorting complexity to O(N) since the range of the prices is [1, 1000]. The overall time complexity is O(N).
Let's prove the correctness of this greedy algorithm. Let the solution produced by the greedy algorithm be A = {a1, a2, ..., ak} and an optimal solution O = {o1, o2, ..., om}.
If O and A are the same, we are done with the proof. Let's assume that there is at least one element oj in O that is not present in A. Because we always take the smallest element from the original set, we know that any element that is not in A is greater than or equal to any ai in A. We could replace oj with the absent element in A without worsening the solution, because there will always be element in A that is not in O. We then increased number of elements in common between A and O, hence we can repeat this operation only finite number of times. We could repeat this process until all the elements in O are elements in A. Therefore, A is as good as any optimal solution.
大体来说和我的思路一致,都是用的贪心策略。
Plates
原题
Problem
Dr. Patel has N stacks of plates. Each stack contains K plates. Each plate has a positive beauty value, describing how beautiful it looks.
Dr. Patel would like to take exactly P plates to use for dinner tonight. If he would like to take a plate in a stack, he must also take all of the plates above it in that stack as well.
Help Dr. Patel pick the P plates that would maximize the total sum of beauty values.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case begins with a line containing the three integers N, K and P. Then, N lines follow. The i-th line contains K integers, describing the beauty values of each stack of plates from top to bottom.
Output
For each test case, output one line containing
Case #x: y, where x is the test case number
(starting from 1) and y is the maximum total sum of beauty
values that Dr. Patel could pick.
Limits
Time limit: 20 seconds per test set. Memory limit: 1GB. 1 ≤ T ≤ 100. 1 ≤ K ≤ 30. 1 ≤ P ≤ N * K. The beauty values are between 1 and 100, inclusive.
Test set 1
1 ≤ N ≤ 3.
Test set 2
1 ≤ N ≤ 50.
Sample
Input
2 2 4 5 10 10 100 30 80 50 10 50 3 2 3 80 80 15 50 20 10
Output
Case #1: 250 Case #2: 180
In Sample Case #1, Dr. Patel needs to pick P = 5 plates:
- He can pick the top 3 plates from the first stack (10 + 10 + 100 = 120).
- He can pick the top 2 plates from the second stack (80 + 50 = 130) .
In total, the sum of beauty values is 250.
In Sample Case #2, Dr. Patel needs to pick P = 3 plates:
- He can pick the top 2 plates from the first stack (80 + 80 = 160).
- He can pick no plates from the second stack.
- He can pick the top plate from the third stack (20).
In total, the sum of beauty values is 180.
Note: Unlike previous editions, in Kick Start 2020, all test sets are visible verdict test sets, meaning you receive instant feedback upon submission.
题目大意
有N叠盘子,每叠盘子的数量为K,每个盘子都有一个美观值。拿盘子有两个限制,一是只能拿P个盘子,二是只能从上往下拿,不能从中间抽出一个来。
问最后拿到的盘子美观值总和最大为多少。
分析
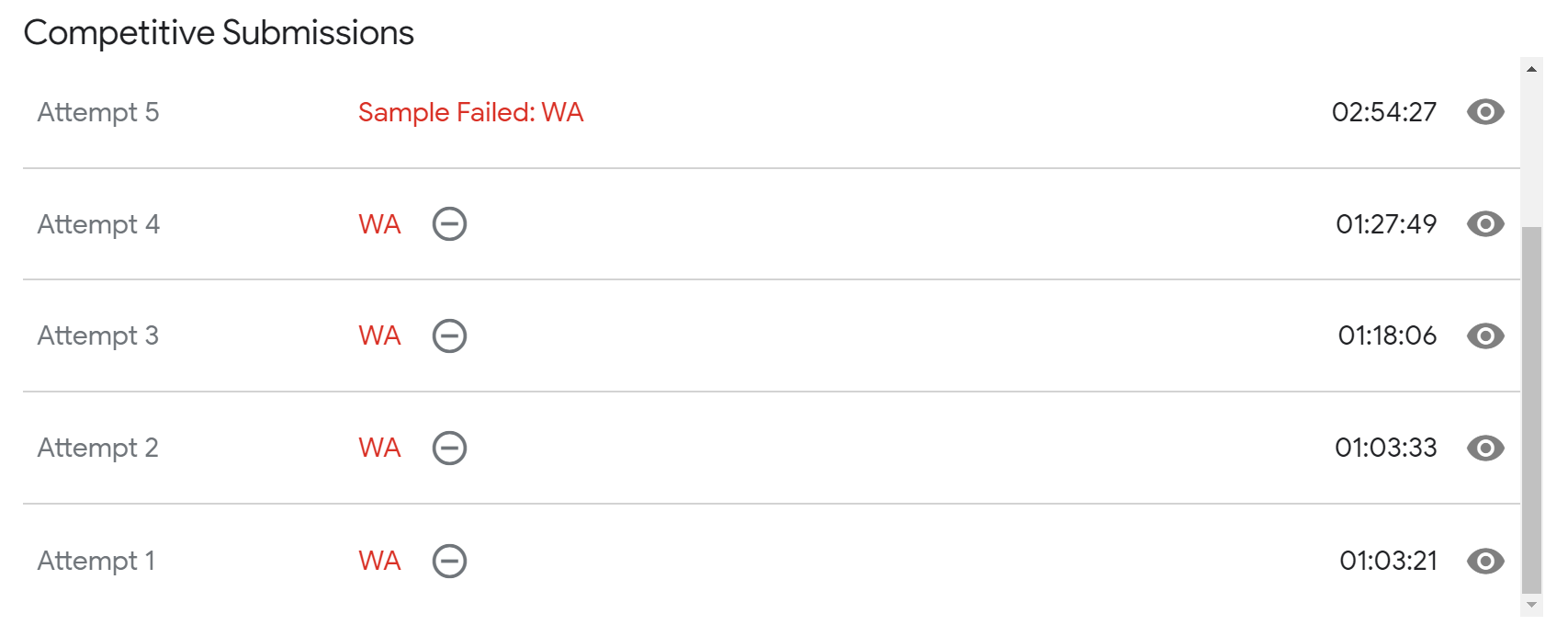
看看我这提交记录,能感觉到我的绝望吗。这题我一开始想的是动态规划的思路,仔细理了一下好像复杂度有点高,不如我想个贪心的策略,于是我想了一个依靠性价比进行的贪心选择策略,感觉没啥问题,可是总是WA(Wrong Answer),后来我知道了我的贪心选择策略有问题。错误代码也就不放出来了,这题只能老老实实动态规划,下面进入正题。
我发现只需要把题目要求好好的理一下,就可以找到动态规划思路的切入点。这题的要求是,在N堆盘子中取P个盘子,要使得美观值最大。N和P这两个变量就是思考切入点,如果我已知在N-1堆盘子中取P个盘子的最大美观值,然后我再加一叠盘子,可以推出在N堆盘子中取P个盘子的最大美观值吗?答案是不行。在我新加的一叠盘子里,假如我取出x个,这x个盘子的美观值是很好计算的,但是这也意味着我前N-1堆盘子里要少拿x个盘子,那么我必须知道在N-1堆盘子中取P-x个盘子的最大美观值。
想到这里,会发现如果我新加一叠盘子,我需要知道的是:
- 如果在新的一叠盘子里取0个盘子,那需要知道在N-1堆盘子中取P个盘子的最大美观值
- 如果在新的一叠盘子里取1个盘子,那需要知道在N-1堆盘子中取P-1个盘子的最大美观值
- …
- 如果在新的一叠盘子里取P个盘子,那需要知道在N-1堆盘子中取0个盘子的最大美观值
当然有可能取不到P个盘子,因为这一堆盘子只有K个,万一P比K大就取不到了。
这就是自顶而下的递归思路,也是动归想法中最重要的一步。
设置dp数组,dp数组有两个维度(我这里用~表示的范围都是左闭右闭区间):
- 第一维长度为N,index范围是0n-1,语义是现在总共考虑从0index的盘子叠
- 第二维长度为P+1,index范围是0~p,语义是总共可以取index个盘子
dp[i][j]表示在前i+1堆盘子中取j个盘子的最大美观值。
写成状态转移方程的话是: \[ dp[i][j] = \max(dp[i][j], dp[i - 1][j - x] + sum[i][x]); \] \(dp[i - 1][j - x] + sum[i][x]\)中\(sum[i][x]\)表示的是仅仅对第i叠盘子操作,取前x个盘子的美观值。这整个式子就表示,当前叠取x个盘子时的总美观值,再与原来的数比较,择优选取。
代码思路
这题需要折腾一个sum数组,也很好办,sum数组也有两个维度:
- 第一维长度为N,index范围是0~n-1,语义是对于第index个盘子叠
- 第二维长度为K+1,index范围是0~k,语义是取前index个盘子
sum[i][j]表示在第i堆盘子中取前j个盘子的美观值。
而初始化sum数组的代码如下:
1 | vector<vector<int> > sum(n, vector<int>(k + 1, 0)); |
也就是个累加和。
接下来是dp数组的初始化部分,我们只需要考虑如果只有第0叠(也就是最前面那叠)盘子,dp数组的值如何。如果只有一叠盘子,那还不是可以拿多少盘子就从折叠拿多少,拿盘子数量限制一个是最多拿p个,还有一个是最多拿k个。
1 | vector<vector<int> > dp(n, vector<int>(p + 1, 0)); |
最后就是dp的主体部分,用到上面所述的状态转移方程:
1 | for (int i = 1; i < n; i++) |
- 第一重循环是从1~n-1,表示新增盘子叠;
- 第二重循环是从1~p,表示总共可以拿多少盘子;
- 第三重循环是从0~min(k,j),表示对于新增的这叠盘子,我打算拿多少。
代码
1 |
|

不容易啊终于过了呜呜呜呜~
官方解法
Analysis
From the constraints, we can see that regardless of the test set, 1 ≤ K ≤ 100. i.e., 1 ≤ P ≤ 100*N.
Test set 1
For this test set, we see that 1 ≤ N ≤ 3. So, we can check for every possible combination of taken plates across all stacks and output the maximum sum. For example, if N = 3 and for any given values of K and P, generate all possible triples (S1, S2, S3) such that S1+S2+S3 = P and 0 ≤ Si ≤ K. Note: Si is the number of plates picked from the i-th stack. This can be done via recursion and the total time complexity is O(KN) which abides by the time limits.
Test set 2
The solution we had for test set 1 doesn't scale given that N now is at most 100. In order to tackle this test set, we use Dynamic Programming along with some precomputation.
First, let's consider an intermediate state dp[i][j] which denotes the maximum sum that can be obtained using the first i stacks when we need to pick j plates in total. Therefore, dp[N][P] would give us the maximum sum using the first N stacks if we need to pick P plates in total. In order to compute dp[][] efficiently, we need to be able to efficiently answer the question: What is the sum of the first x plates from stack i? We can precompute this once for all N stacks. Let sum[i][x] denote the sum of first x plates from stack i.
Next, we iterate over the stacks and try to answer the question: What is the maximum sum if we had to pick j plates in total using the i stacks we've seen so far? This would give us dp[i][j]. However, we need to also decide, among those j plates, how many come from the i-th stack? i.e., Let's say we pick x plates from the i-th stack, then dp[i][j] = max(dp[i][j], sum[i][x]+dp[i-1][j-x]). Therefore, in order to pick j plates in total from i stacks, we can pick anywhere between [0, 1, ..., j] plates from the i-th stack and [j, j-1, ..., 0] plates from the previous i-1 stacks respectively. Also, we need to do this for all values of 1 ≤ j ≤ P.
The flow would look like:
1 | for i [1, N]: |
If we observe closely, this is similar to the 0-1 Knapsack Problem with some added complexity. To conclude, the overall time complexity would be O(NPK).
第一个解法就是暴力搜索,第二个是动归思路,我的想法就是从这里学的,看这里的解法更加原汁原味,值得品一下。
Workout
原题
Problem
Tambourine has prepared a fitness program so that she can become more fit! The program is made of N sessions. During the i-th session, Tambourine will exercise for Mi minutes. The number of minutes she exercises in each session are strictly increasing.
The difficulty of her fitness program is equal to the maximum difference in the number of minutes between any two consecutive training sessions.
To make her program less difficult, Tambourine has decided to add up to K additional training sessions to her fitness program. She can add these sessions anywhere in her fitness program, and exercise any positive integer number of minutes in each of them. After the additional training session are added, the number of minutes she exercises in each session must still be strictly increasing. What is the minimum difficulty possible?
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case begins with a line containing the two integers N and K. The second line contains N integers, the i-th of these is Mi, the number of minutes she will exercise in the i-th session.
Output
For each test case, output one line containing
Case #x: y, where x is the test case number
(starting from 1) and y is the minimum difficulty possible
after up to K additional training sessions are
added.
Limits
Time limit: 20 seconds per test set. Memory limit: 1GB. 1 ≤ T ≤ 100. For at most 10 test cases, 2 ≤ N ≤ 105. For all other test cases, 2 ≤ N ≤ 300. 1 ≤ Mi ≤ 109. Mi < Mi+1 for all i.
Test set 1
K = 1.
Test set 2
1 ≤ K ≤ 105.
Samples
Input 1
1 3 1 100 200 230
Output 1
Case #1: 50
Input 2
3 5 2 10 13 15 16 17 5 6 9 10 20 26 30 8 3 1 2 3 4 5 6 7 10
Output 2
Case #1: 2 Case #2: 3 Case #3: 1
Sample #1
In Case #1: Tambourine can add up to one session. The added sessions are marked in bold: 100 150 200 230. The difficulty is now 50.
Sample #2
In Case #1: Tambourine can add up to six sessions. The added sessions are marked in bold: 9 10 12 14 16 18 20 23 26 29 30. The difficulty is now 3.
In Case #2: Tambourine can add up to three sessions. The added sessions are marked in bold: 1 2 3 4 5 6 7 8 9 10. The difficulty is now 1. Note that Tambourine only added two sessions.
- Note #1: Only Sample #1 is a valid input for Test set 1. Consequently, Sample #1 will be used as a sample test set for your submissions.
- Note #2: Unlike previous editions, in Kick Start 2020, all test sets are visible verdict test sets, meaning you receive instant feedback upon submission.
题目大意
有一串序列是严格递增的,定义一个难度量,计算方式是序列中所有相邻两个数之差的最大值,比如13, 19, 22,相邻两数之差是 6, 3,那么难度就是最大值6。会发现如果插入一个数进去会减小难度,比如在13,19中间插入16,那么相邻两数之差是 3, 3, 3,难度为3。本题就是给一串序列,再给一个限制允许插入几个数,求插入后最小的难度是多少。
分析
又是一道翻车题,本来一看题我都傻眼了,这不是直接无脑找最大的两数之差,然后往中间塞一个数,如此反复知道全部用完就好吗。代码也很简单,直接放出来:
1 | int solve(int k, vector<unsigned long long> &minutes) |
可是事实呢,事实不咋地。

第二个测试集出现了WA,我也是思前想后不知道问题出在哪。我无意间又瞥了一眼样例,发现有个地方不太对劲。
5 6 9 10 20 26 30
就这个,但是要稍微做一点修改,改成
3 5 10 20 23
会发现如果按我的解法,那应该是在10和20中间塞15,然后再在10和15间塞12,15和20间塞17,再塞13和18,这时变成
10 12 13 15 17 18 20 23
此时最大间隔是20-23,差值为3。
但是明明可以有更好的解法,那就是
10 12 14 16 18 20 21 23,此时最大差值是2。
会发现1020这个间隔只需要4个数就可以把差值降成2,省了一个数去降2023,而我用完了5个数,我的解法一定有问题。
这题也是看了解答才有的思路,关键在于逆向思维。既然不知道怎么切分得到最佳难度值,那么我就搜索难度值,找出一个最优解。
如何判定一个难度值是合法的?
- 可以通过难度值得到,这个间隔i需要切分多少次K_i
- 把所有间隔的切分次数累加成总切分次数K_sum = K_1 + K_2 + … + K_n
- 如果K_sum <= K,那么就合法。
还有个问题,步骤1里面怎么知道间隔i需要切分多少次呢?
如果间隔长度为d_i,切分次数为K_i,难度值为d_o,有 \[ d_o \times (K_i + 1) \geq d_i \] 不难得出 \[ d_o = \left \lceil\frac{d_i}{K_i + 1}\right \rceil \] 官方给的计算公式是这个 \[ K_i = \left \lceil\frac{d_i}{d_o}\right \rceil - 1 \] 我实在是没办法从上一步推到下一步,这里留个坑,如果有大佬能帮忙解决我将感激不尽,并有大红包感谢。
得到这个公式,接下来算\(K_{sum}\)也不难,是一个求和 \[ K_{sum} = \sum_{i=1}^{n} K_i \] 如果K_sum <= K,那么就合法。
另外本题K_i还有个计算公式: \[ K_i = \left \lfloor\frac{d_i - 1}{d_o}\right \rfloor \] 我这是从大佬代码里看得的,不知道怎么证明(我真是太菜了),一样求证明!
代码
1 |
|
官方解法
Analysis
Test set 1
Since K=1, all that we need to do is to find the maximum difference and split it into 2 halves. For example, given a sequence [2, 12, 18] and K = 1, the difficulty is 10, since the maximum difference is in [2, 12]. The best way to minimize this is to take the maximum difference and split it in half giving us the final sequence of [2, 7, 12, 18]. The difficulty for this final sequence now is 6. The time complexity is O(N).
Test set 2
For this test case, we cannot perform such direct splits because repeatedly splitting the maximum difference into halves is not optimal. For example, given a sequence [2, 12] and K = 2, splitting into halves will result in [2, 12] → [2, 7, 12] → [2, 7, 9, 12]. This way, the difficulty would be 5. However, if we perform [2, 12] → [2, 5, 12] → [2, 5, 8, 12], the difficulty would be 4. This clearly demonstrates that continuous halving of the maximum difference is sub-optimal. Okay, so how do we do this?
Consider the i-th adjacent pair of training sessions with an initial difference di. If we want to insert some number of training sessions in between this pair such that the maximum difference among those is at most a certain value, let's say doptimal, then how many training sessions can be inserted in between? The answer to this is ceiling(di / doptimal)-1. Let's call that k'i. Doing this for all N-1 adjacent pairs in the given array would give us k'[1, ..., N-1]. Let's denote k'sum = k'1+k'2+ ....+k'N-1. From the constraints, we can insert at most K training sessions. Therefore, we need to make sure k'sum ≤ K while minimizing doptimal as much as possible.
If you observe, doptimal can lie anywhere between [1, max(di)] (1 ≤ i ≤ N-1). Linear search would be to check every value here starting from 1 and output the first value that satisfies the above condition. A quicker way to do this is using binary search. On closer observation, you can see that increasing the value of doptimal decreases the value of ceiling(di / doptimal)-1 and hence smaller is the value of k'sum. Therefore, we can perform a binary search in the range [1, max(di)] to find the least value of doptimal that makes k'sum ≤ K. That is our answer.
Since the max(di) could be as much as 109, we might have to search [1, 109] making time complexity of the solution is O(log(109)*N).
差不多就我上面写的那些,可以再读读原文。
Bundling
原题
Problem
Pip has N strings. Each string consists only of
letters from A to Z. Pip would like to bundle
their strings into groups of size K. Each
string must belong to exactly one group.
The score of a group is equal to the length of the longest prefix shared by all the strings in that group. For example:
- The group
{RAINBOW, RANK, RANDOM, RANK}has a score of 2 (the longest prefix is'RA'). - The group
{FIRE, FIREBALL, FIREFIGHTER}has a score of 4 (the longest prefix is'FIRE'). - The group
{ALLOCATION, PLATE, WORKOUT, BUNDLING}has a score of 0 (the longest prefix is'').
Please help Pip bundle their strings into groups of size K, such that the sum of scores of the groups is maximized.
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each test case begins with a line containing the two integers N and K. Then, N lines follow, each containing one of Pip's strings.
Output
For each test case, output one line containing
Case #x: y, where x is the test case number
(starting from 1) and y is the maximum sum of scores
possible.
Limits
Time limit: 20 seconds per test set. Memory limit: 1GB. 1 ≤
T ≤ 100. 2 ≤ N ≤ 105. 2 ≤
K ≤ N. K divides
N. Each of Pip's strings contain at least one
character. Each string consists only of letters from A to
Z.
Test set 1
Each of Pip's strings contain at most 5 characters.
Test set 2
The total number of characters in Pip's strings across all test cases is at most 2 × 106.
Samples
Input 1
2 2 2 KICK START 8 2 G G GO GO GOO GOO GOOO GOOO
Output 1
Case #1: 0 Case #2: 10
Input 2
1 6 3 RAINBOW FIREBALL RANK RANDOM FIREWALL FIREFIGHTER
Output 2
Case #1: 6
Sample #1
In Case #1, Pip can achieve a total score of 0 by make the groups:
{KICK, START}, with a score of 0.
In Case #2, Pip can achieve a total score of 10 by make the groups:
{G, G}, with a score of 1.{GO, GO}, with a score of 2.{GOO, GOO}, with a score of 3.{GOOO, GOOO}, with a score of 4.
Sample #2
In Case #1, Pip can achieve a total score of 6 by make the groups:
{RAINBOW, RANK, RANDOM}, with a score of 2.{FIREBALL, FIREWALL, FIREFIGHTER}, with a score of 4.Note #1: Only Sample #1 is a valid input for Test set 1. Consequently, Sample #1 will be used as a sample test set for your submissions.
Note #2: Unlike previous editions, in Kick Start 2020, all test sets are visible verdict test sets, meaning you receive instant feedback upon submission.
官方解法
Analysis
We need to maximise the sum of scores of each bundle. Let us consider a bundle and say longest prefix shared by all strings of this bundle is of length X. Now each prefix of length from 1 to X is shared by all of the strings in this bundle. Consider any prefix among these X prefixes, it is counted once in the score of this bundle. Thus the score of a bundle can be defined as number of prefixes that are shared by all of the strings in this bundle. Thus if a prefix is shared by all strings in Y bundles, then it will contribute Y to the total sum of scores.
Now instead of finding the total score, we find the contribution of each prefix in the total score. So for maximising the total score, we would want to maximize the contribution of each prefix in the total score. Let the contribution of each prefix PRE be contibution(PRE). We want to maximize ∑ contribution(PRE) where PRE comprises all possible prefixes of the given strings.
Let us say a prefix Pi is a prefix of S strings. The maximum number of bundles of size K formed by S strings is ⌊ S / K ⌋. In each of these ⌊ S / K ⌋ bundles, prefix Pi will add to their scores. Thus maximum value of contribution(Pi) can be ⌊ S / K ⌋. So a prefix Pi which occurs as a prefix of S strings will contribute ⌊ S / K ⌋ to the answer.
Let us see if we can achieve this maximum value for all the prefixes. Consider a prefix P of length L. It occurs as a prefix in CNT number of strings. Now consider there are C prefixes of length L + 1 which contain the prefix P as a prefix (P1, P2, ....,PC). And we have stored the number of strings these prefixes are part of as (CNT1, CNT2, ....,CNTC).
Let us say we divided the strings which have prefix Pi into ⌊ (CNTi / K) ⌋ bundles. Now we have CNTi%K strings remaining for each prefix that we need to arrange so that they make a bundle. For each of these remaining strings we cannot have a bundle of size K which would have a common prefix of length L + 1 because we have CNTi%K remaining strings for each Pi. So, we can make bundles in any order using the remanining strings. Those bundles will still have a prefix of length L shared among them. Thus we would be left with CNT%K number of strings which are not in any bundle when we consider prefix P. We can continue this procedure till we are left with prefix of length 0. We would be able to bundle all the strings at this point because we would have N % K strings remaining, and as specified in the problem, N is divisible by K.
The problem is now reduced to finding number of times each prefix occurs in the given strings. Let this number be COUNT. We just need to add ⌊ COUNT / K ⌋ to the answer for each prefix.
Test set 1
The length of each string is at most 5. Thus we have total number of prefixes as N * 5 and each prefix can be of size at most 5. Store each prefix in a hashmap and increase the count for each prefix. In the end, we just need to add ⌊ (count(i) / K) ⌋ for each prefix i. The complexity of the solution would be O(N * 5 * 5).
Test set 2
Let the sum of length of all strings over all the test cases be SUM which is 106. For the large test set, the length of the string can be very large. So, we can't store all the prefixes in a hashmap. We need to store all the prefixes in an efficient manner along with the number of times they occur in given strings. We can use a data structure trie. The insertion cost would be equal to sum of length of strings over the test cases which is O(SUM). Then finally we just need to traverse the trie and for each prefix, add its contribution to the answer. Time complexity of the solution would be O(SUM).
留坑
这题我比赛时扫了一眼题目,没思路就没做,后面再填坑吧。
最后总结
这是我第一次参加Google Kick Start,不知怎么谷歌给我发了这个邮件,也是在机缘巧合下报了名,现在看来题目难度还是不小,但是都很有意思。有些题目真的一反我的直觉解法,让我面对WA两个字苦闷绝望了一个小时。不过我还是学到不少东西的,一个月后的Round B继续加油吧。
